[KT AIVLE School(에이블스쿨)] - 11주차 후기(미니프로젝트 4차)
에이블 스쿨 11주차(10.16 ~ 10.20) - 4기 AI트랙
프로젝트 후기라 쓰고 나의 힘들었던 회고라 읽는다.
미니프로젝트 4차
4차 미프 3-7일차 주제 : 1대 1 문의 내용 유형 분류기
주어진 데이터 : 에이블스쿨 2기분들의 문의 게시판 내용 데이터
데이터 구성 : 문의내용, 질문유형(이론, 시스템 운영, 코드1, 코드2, 원격, 웹)
목표 : 질문 게시판의 에이블러들의 질문 유형을 자동으로 분류해 주는 모델을 만들고 성능을 향상시키는 것
3일차
첫날은 주어진 데이터를 불러와 탐색하는 과정을 거쳤다.
데이터 탐색을 위해 문의내용인 text의 최소, 최대길이를 확인하며 그중 최대 길이의 문의내용은 오류 코드를 그대로 올린 것이었다.
그리고 문의내용에 품사 태깅과 명사를 추출하는 과정을 진행하였다.
Mecab을 활용하여 pos함수를 통해 품사 태깅을 진행했고 nouns 함수를 통해 명사를 추출해 보았다. 명사를 추출하면 한글 명사만 결과로 보이길래 형태소별로 나눌 수 있는 morphs 함수가 있어 추가적으로 사용해 보았다.
텍스트를 분석하기 위해 nltk Text로 변경하여 Type-Token Ratio을 확인하였다.
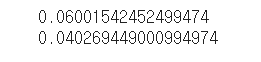
명사를 추출한 데이터의 Type-Token Ratio : 0.06
품사를 추출한 데이터 Type-Token Ratio : 0.04
빈도수가 많은 단어를 시각화하기 위해 nltk의 FreqDist를 불러와 plot 그리기

▶ 빈도수가 높은 상위 15개의 명사(것, 수, 값, 데이터 ...)
collocation(연어) 확인을 위해 Bigram을 이용하여 빈도수가 50 이상인 상위 15개의 결과
▶ [('결', '측'), ('딥', '러닝'), ('튜', '터'), ('머신', '러닝'), ('미니', '프로젝트'), ('인', '스턴스'), ('원격', '지원'), ('코딩', '마스터스'), ('셀프', '테스트'), ('데이터', '프레임'), ('안녕', '튜'), ('에러', '발생'), ('실습', '피드백'), ('오류', '발생'), ('첨부', '파일')]

▶ 명사 추출한 데이터를 통해 WordCloud 그리기
4일차
두 번째날은 데이터 전처리를 본격적으로 시작하였다.
특수문자를 제거하기 위해 파이썬 정규표현식을 이용하여 함수를 작성하였고 ngram을 통해 CountVectorizer, TfidfVectorizer을 이용하여 텍스트 데이터를 학습시켜 고유한 단어의 수도 확인해 보았다.
ngram을 처음 접해보아서 왜 사용하는지, 사용 방법이 무엇인지에 대해 이해하고 공부하는 시간을 더 많이 가졌었다...
또한, 주어진 텍스트에 관해 단어 사전을 생성하여 길이 분포를 확인해 보며 이용할 텍스트 데이터를 신경망 모델에 입력하기 위해 정수 시퀀스로 변환해 보았다.
위 두 가지 실습(ngram, sequence)은 혼자 이해하고 진행하는데 어려움이 있어서 좀 힘들었지만.. 강사님 설명도 다시 듣고 팀원들과 의견공유를 통해 조금이나마 더 이해할 수 있었다.
(좀 더 공부해서 정리하여 내용을 추가해봐야겠다 !!!!!!!!!!!!!!!!!!)
결론 : 전처리 너무 중요한데 너무 버겁다 ㅜ
5일차
세 번째날부터 시작한 모델링 시간이다.
머신러닝 모델링을 진행하였고 나는 LogisticRegression, RandomForest, XGB 모델을 사용했는데 각각 정확도는 0.83, 0.77, 0.79 로 나왔다.
팀원분들의 의견도 들어보니 SVM도 꽤 잘 나온다 해서 진행해 보니 0.83이 나왔고 다른 분들은 배우지 않은 머신러닝 모델들을 사용하여 더 높은 정확도를 뽑아내기도 하였다.
역시 스스로 찾아보고 시도하면서 공부하는 게 중요한 것 같다 하하
모델 튜닝도 추가적으로 진행해 보았는데, GridSearch을 사용하여 머신러닝 모델 중 높은 정확도를 보인 SVM 모델로 하이퍼파라미터 튜닝을 시도해 보았다. 근데... 실행시간이 16분? 정도로 꽤 오래 기다려서 결과를 확인해 봤는데 정확도는 크게 높아지지 않았고 어쩔 때는 더 떨어지기도 하여서.. 다른 튜닝 방법을 도전해 보아야겠다!!
6일차
네 번째날은 딥러닝 모델링을 진행하였고 DNN, 1-D CNN, LSTM을 각각 만들어 시도해 보았다.
간단하게 층을 만들어서 정확도를 확인해 보니 0.4 ~ 0.5 정도의 낮은 정확도가 나와서 이것저것 검색하며 알아보니 텍스트 데이터와 같이 범주형 데이터를 신경망 입력으로 사용하는 Embedding 레이어가 있었다. Embedding 레이어를 추가하여 다시 모델링을 해보니 각각 0.75, 0.77, 0.80의 정확도를 도출해 낼 수 있었다.
추가적으로 pre-trained 모델 사용을 위해 팀원분이 공유해 준 블로그를 참고하여 klue-bert 모델을 이용하여 모델링을 진행하니 0.83 정도의 정확도가 나왔다. 하지만 이 모델은 전처리하기 전의 데이터를 이용했었고.. 전처리한 데이터를 이용해서 다시 모델링을 한다면 좀 더 높은 정확도가 나오지 않을까 싶어서 검색도 많이 해보고 시도했는데...
내게 남는 건 여러 종류의 오류뿐 ,, ^~^
7일차
미프 4차 마지막날은 이전까지 직접 모델링한 것을 가지고 팀별로 캐글 대회를 진행하였다.
pre-traind 모델 성능이 잘 나온다 해서 이 모델로 조금씩 수정을 해보고 성능을 높이고 싶었지만 마음처럼 쉽게 되지는 않았다..
그래서 나는 머신러닝 모델 중 성능이 높게 나온 LogisticRegression과 SVC 모델을 사용해 보기로 했다. BorderlineSMOTE를 이용해서 데이터 oversampling을 진행하여 이 데이터를 가지고 RandomSearch와 GridSearch를 통해 정확도 0.86까지 도출해 낼 수 있었다.
이 모델을 가지고 한 번 캐글에 올려서 평가받고 싶었다 !!!
결과는
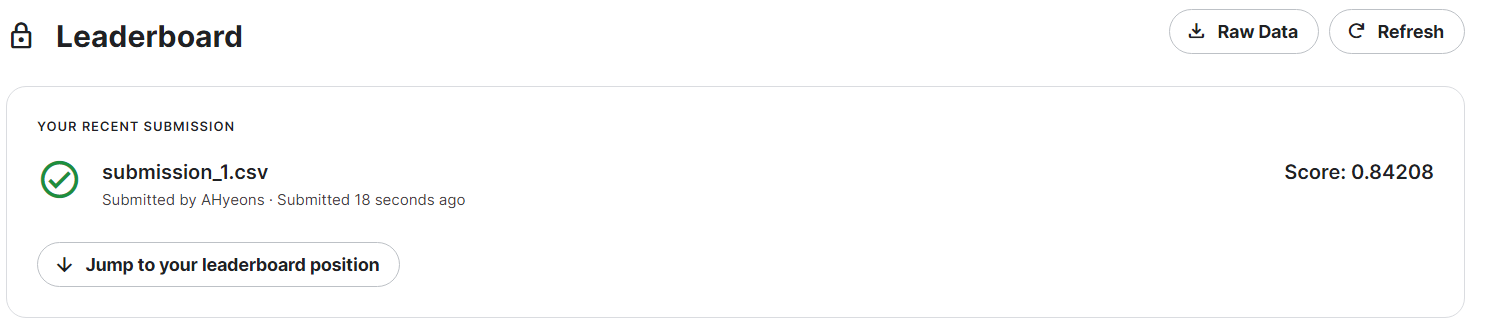
0.84208 .. 역시나 조금 더 떨어진 값이 나왔다.
아쉽기도 했지만 전처리된 데이터를 가지고 머신러닝 모델 정확도를 더 높이기엔 한계가 있다고 생각했다. 이전에 모델링했던 klue-bert 모델을 가지고 혼자 끙끙 여러 시도를 해보고 있는데..
우리 팀원분들이 0.86...0.87...이렇게 결과가 나오더니 결국 0.88까지 도달하여 최종적으로 랭킹 3위를 달성했다. 폼 미쳤다,,,
다들 열정적이시고 열심히 하시는 분들이라 너무 멋있었다. 나 빼고 다 잘행 ദ്ദി˙∇˙)ว
팀원분이 사용한 모델도 bert 모델이었는데 그중 한국어 모델의 한 예인 kcbert였다.
한국어 텍스트에 대해 처리를 더 정확하게 수행할 수 있도록 조정된 모델이라 한다 !!!
모델링하신 코드를 확인했지만 아직 제대로 이해하기엔 어려움이 있었다,,ㅎㅎㅎ
이렇게 더 배워가는 것이라 생각하며 .. 이번 프로젝트는 나에게 많은 어려움이 있어서 답답하고 가끔 머리가 아팠지만 시간 가는 줄 모르고 열심히 모델링을 시도해 보고 처음 캐글도 진행해 보니 흥미로웠고 값진 경험이라고 생각한다 ₍꒢ ̣̮꒢₎